Python Asyncio

It’s been a while since I delved into Python’s asyncio module. Back in 2018, I became familiar with it, while working
on a massive machine learning pipeline for Bitdefender. It was the asyncio feature that allowed us to scale the entire thing without
needing to grow the number of CPU cores linearly, which as you can imagine, saved quite a bit of money.
Fast-forward to 2024, I’m maintaining the python-arango driver, which is
synchronous by design. I’ve always wanted to write about asyncio, because I think it’s such a game changer for Python developers.
Now that I started working on the long-awaited python-arango-async,
it’s a great opportunity to synthesize my knowledge here. This article is intended as a quick reference on the topic,
giving enough context to navigate the asyncio waters with confidence.
Introduction
Synchronous code
Let’s start with a simple synchronous server that converts a decimal number to hexadecimal.
5 | with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s: |
This is pretty basic. It’s listening on port 65432, accepts a connection, then reads the data sent by the client,
parses it as an integer, converts it to hexadecimal, and sends it back.
You can interact with it using nc localhost 65432:
1 | 4312 |
But, try connecting with two clients at the same time. If we run nc localhost 65432 in two separate terminals, the second
one will hang until the first one closes the connection. The problem is that I/O operations are blocking, which means
the server blocks every time it reads or writes data.
What happens internally, on Linux, is that client.recv(1024) eventually gets into a low-level read(fd, buf, 1024)
system call. Getting deeper, the instructions for doing a read system call look like this:
1 | mov rax, 0 ; syscall number for read |
A syscall is just a mechanism used by the kernel to provide services to user-space applications. It used to be int 0x80
on 32-bit systems, but nowadays, you’ll find syscall in most programs. When the kernel receives a read syscall,
it will block the calling thread until the data is available.
Threads
Using threads is a common way to work around blocking I/O. We can create a thread for each client connection, so that the server can handle multiple clients concurrently. As you might know already, threads cannot be used to parallelize CPU-bound tasks, because of Python’s GIL . But for I/O-bound tasks, they work just fine. Here’s the same example turned into multithreaded code:
5 | def handle_client(conn): |
The problem is fixed and we can now connect with multiple clients at the same time. You can open as many netcat connections
as you want and they will all work. So, why bother with asyncio at all if the solution is already there?
Well, threads are not without their own problems. For a simple web server, it’s not going to
make a difference. But for complex applications, threads can be a nightmare to work with. First of all, they have a
high memory overhead. I’m talking 1000’s of threads here. Each thread allocates its own stack, which is usually between
1 and 10 MB - that’s an average of 5 GB for 1000 threads. Apart from that, context switching is not free. The kernel
needs to save the state of the current thread and load the state of the next one. This is a costly operation, especially
when you have many threads. The thread scheduler is OS dependent, which means you have little to no control over it.
But, this is not at all a rant against threads. The easiest solution is often the best one. However, when you need to scale to hundreds or even thousands,
you’ll reach a different kind of problem.
You see, when we go down that rabbit hole, we’ll eventually arrive to an event loop:
a single thread that continuously checks for and dispatches events, allowing asynchronous processing of I/O operations.
Asyncio
The asyncio example doesn’t look too different from the previous ones:
4 | async def handle_client(reader, writer): |
Now there’s only one thread, but the server has the capabilities to handle multiple clients concurrently. More so, the code
doesn’t contain any callbacks or event listeners. It’s just like a regular synchronous code, but with a few await keywords sprinkled
here and there.
The even loop manages the execution of coroutines, scheduling them and switching between them at await points. An async function
is a coroutine, which means it can pause its execution and resume it at a later point.
The await keyword yields control back to the event loop, which will resume the coroutine after the operation is done.
Note that we need the following line in order to run the server:
28 | asyncio.run(main()) |
This is because async functions cannot run on their own. asyncio.run() tells the event loop to schedule the coroutine.
How it works
Turns out, there’s a way to mark a file descriptor as non-blocking.
1 | int flags = fcntl(fd, F_GETFL, 0); |
When reading from such a file descriptor, the kernel returns immediately if there’s no data available, instead of blocking the thread. Using system calls such as poll or epoll one can monitor multiple file descriptors to see if I/O is possible on any of them. There have been ways to do achieve this in Python before asyncio, although they were not as easy to use. In hindsight, asyncio is the perfect abstraction for this kind of work, making in platform-independent. This is the essence of the event loop.
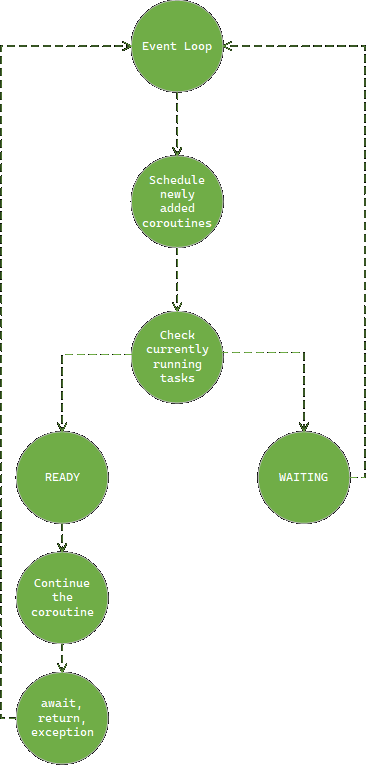
asyncio.run() simply schedules a new task on the event loop. await tells the event loop that we’re about to do an
asynchronous operation, so it can switch to other tasks in the meantime. The event loop will resume the coroutine when
the operation is done. From a high-level perspective, this is actually quite simple, but it begs the question: “How does
the event loop handle context switching?”. To answer that, let’s see what happens if we call an async function just
as if it were one of our regular functions:
1 | async def foo(): |
It actually returns a coroutine object:
1 | >>> foo() |
What can you do with it? Can you treat it as a generator?
1 | def foo_generator(): |
In the generator’s case, the output looks like this:
1 | bar |
Sending None results in a StopIteration exception. See what happens if we do that with our foo coroutine:
1 | coro = foo() |
The coroutine prints bar and raises a StopIteration exception, just like the generator:
1 | bar |
So, we actually managed to run the coroutine as if it were a generator. Generators are the magic behind asyncio. And the best part is that you don’t need to know that in order to use them. The abstraction is so good that you can choose between multiple event loop implementations, such as uvloop or tornado with minimal changes to your code.
In practice
There’s plenty of things you can do with asyncio, but I’m going to present here the most common use cases.
CPU-bound tasks
The most important thing is to make sure you to not block the event loop while running CPU-bound tasks. Remember that the event loop
doesn’t run in parallel, it rather switches between tasks, taking control whenever an await is encountered.
A long-running task which never awaits will prevent the event loop from scheduling other tasks, effectively blocking the entire application.
If you need to run a CPU-bound task, you can use the run_in_executor
function to execute it in a separate process:
1 | def cpu_bound(): |
Blocking IO
If say 90% of your code is asynchronous, but you must integrate a library that only provides synchronous IO, you don’t need a separate process for that - threads will do just fine. Use asyncio.to_thread to schedule the synchronous function in a separate thread:
1 | def blocking_io(): |
Networking
HTTP Requests
For regular networking operations, my two favorite libraries are httpx and
aiohttp.httpx is a bit more high-level, and it also supports synchronous code. It’s very easy to integrate it in your application
and has great documentation.
1 | async with httpx.AsyncClient() as client: |
aiohttp is more powerful, but also more complex. In terms of performance, it is a fast framework, and it offers low-level control
over its components. It also comes with a fully functional web server. This would be my choice for a heavy-duty application.
1 | async with aiohttp.ClientSession() as session: |
If you don’t need any advanced features, I suggest you go with httpx.
Sanic
My go-to async web server is Sanic. It is very popular, fast and scales well. Their documentation is great. It’s a mature project and you can find lots of examples online. The API is very similar to Flask, so you’ll feel right at home coming from the synchronous world.
1 | from sanic import Sanic, Request, json |
Asynchronous iterators
As a counterpart to synchronous iterators, asynchronous iterators
can implement __aiter__ and __anext__ methods. Note that __anext__ should raise a StopAsyncIteration exception when
the iterator is exhausted, instead of StopIteration, and __aiter__ is not an async method.
4 | class AsyncFibo: |
You would have to use async for to iterate over the items:
23 | async for num in AsyncFibo(7): |
An async generator can be used in a similar manner:
4 | async def async_fibo(limit): |
Asynchronous context managers
Context managers can also be asynchronous, by implementing __aenter__ and __aexit__ methods.
1 | class AsyncResource: |
Here’s how to read from a file asynchronously:
1 | async with aiofiles.open('file.txt', mode='r') as f: |
Tasks
A Task is a convenient wrapper around a coroutine.
It can be awaited, cancelled, or have callbacks attached to it. You can wrap a coroutine using the create_task function:
1 | task = asyncio.create_task(my_coroutine()) |
Not to be confused with a Future, which is a low-level object that represents the result of an asynchronous operation.
There’s many things you can do with tasks, out of which the most common is waiting for multiple tasks to complete.
asyncio.gather
Returns a single future aggregating the results of all provided coroutines. The results are returned in the order the coroutines were provided.
1 | await asyncio.gather(coro1(), coro2()) |
asyncio.wait
It does not aggregate results but allows more control over task completion. It returns two sets of tasks: those that are completed and those that are still pending. You can specify different waiting conditions such as waiting for all tasks to complete or waiting for the first one to complete.
1 | tasks = [asyncio.create_task(fetch_data(url)) for url in urls] |
Locks
Although we’re working with a single-threaded model, there are still cases where you need to synchronize access to shared resources. For example, you might want to synchronize access to a database. Suppose you have the following code which overwrites the value of a key if it is not already set:
1 | lock = asyncio.Lock() |
When we execute both functions concurrently, we have no way of knowing which will run first. Recall that await yields control
back to the event loop, which might continue with other tasks before resuming the current one. This means that the execution
of both functions is segmented by await points. Therefore, is possible that both functions will check if the key exists
one after the other, find out there’s no key, and then and both will insert the key-value pair. This is where locks come in.
Only one coroutine can acquire the lock at a time, so the second one will have to wait until the first one releases it.
Conclusion
asyncio is Python’s way of implementing cooperative multitasking. Things are continuously improving, with Python 3.11
making significant improvements that directly benefit asyncio. It is already a major part of the ecosystem.
There’s lots of things you can use it for, but it is not a silver bullet. You should be aware of its limitations and
use it where it makes sense. Keep in mind that a simple solution is often the best choice.